Inverted Index Nedir?
Yazı hakkında bir yorum bırakmak için tıklayın.
Bu yazıya sizde katkıda bulunabilirsiniz.
Text tabanlı bir döküman kümeniz olduğunu düşünün. Bu dökümanlar içerisindeki terimlerinizi bu terimlerin hangi dökümanlar ile ilişkili olduğunu dökümanın bilgisini bir yerde tuttuğunuzu düşünün. Bu terimler içerisinde bir arama yaptığınızda terimlere karşılık gelen dökümanları hızlıca bulabileceksiniz. Yani siz dökümanlarınıza terimler üzerinden ulaşıyor olacaksınız. İşte buna inverted(ters) index denir.
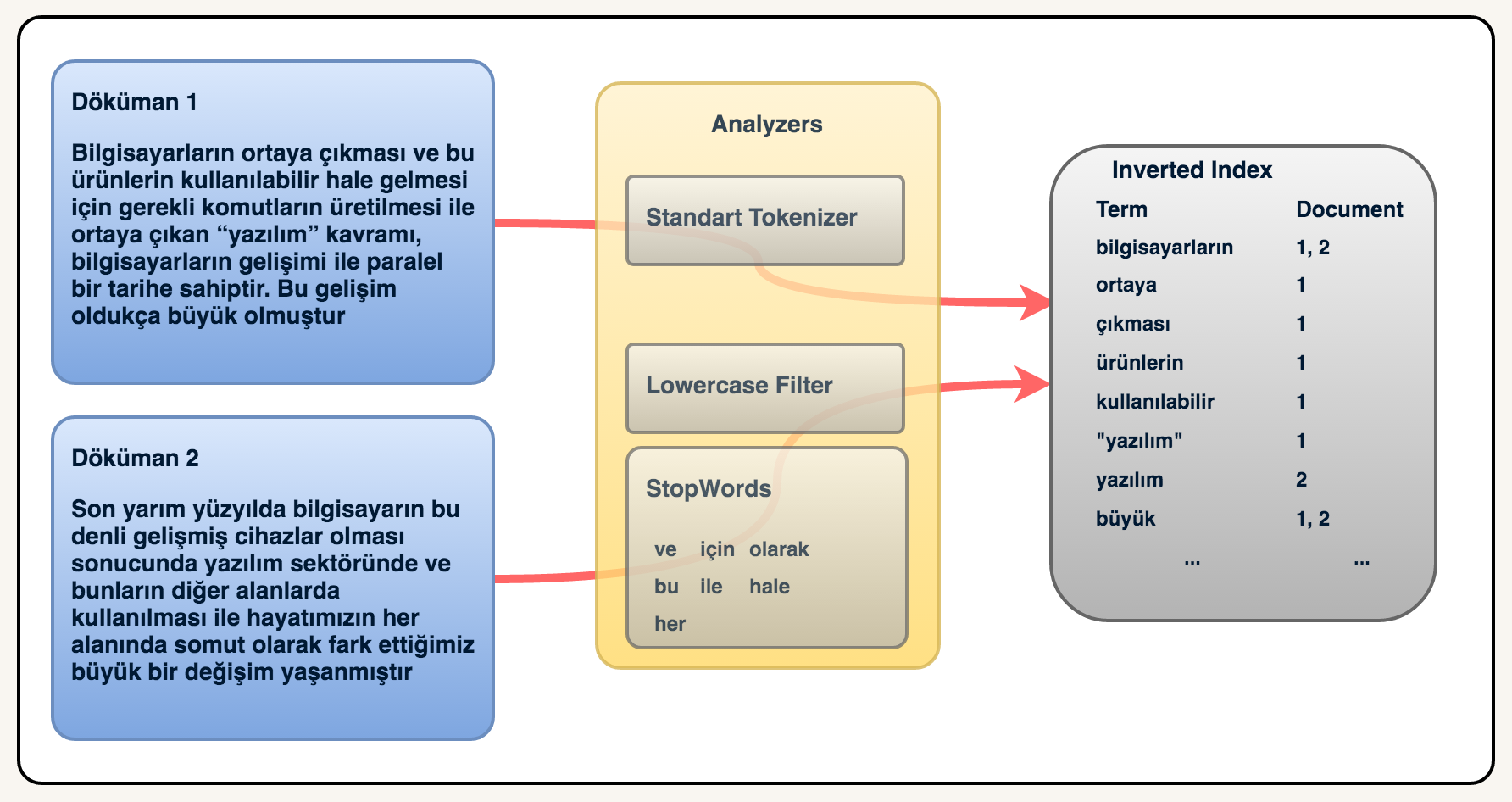
Aşağıdaki örnekte inverted index kavramını görsel olarak daha iyi anlayabilirsiniz.
Burada dikkat edilmesi gereken bir diğer önemli kısımda analyzers kısmıdır. Burada
bizim metnimizi bir takım tokenizer ve filterlardan geçirerek inverted index olarak
kaydediyoruz. Aşağıdaki örnekte veriler sırasıyla Standart Tokenizer, Lowercase Filter
ve Stopwords Filter‘dan geçirilmektedir. Daha sonrada inverted index olarak
kaydedilmektedir.
Burada ekstra olarak bir terimin döküman içerisindeki pozisyonunu da kaydettiğinizi düşünürsek kolayca terim için her döküman karşılık bir puan da çıkarabilirsiniz ve aramalarda bunu sonuçları sıralamak için kullanabilirsiniz.
Aşağıdaki örnekte ise aynı dökümanı inverted index’e kaydederken dökümandaki terimlerin döküman içerisindeki pozisyonları ile birlikte kaydettik. Mesela “bilgisayarın” terimi
- döküman içerisinde 2 yerde geçmektedir ve sırasıyla 1. ve 14. sıradadırlar.
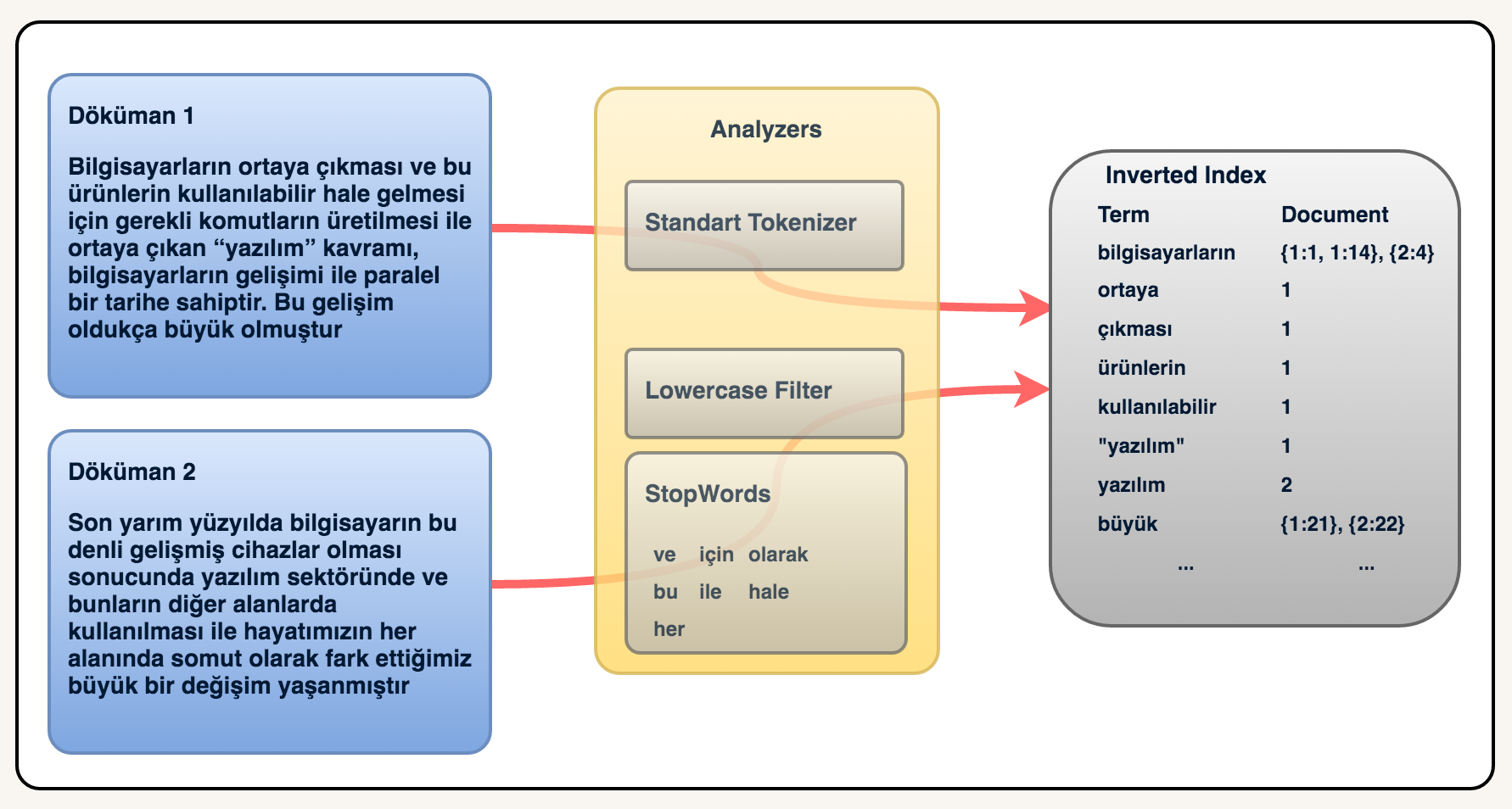
Bir arama yaparken ise inverted index’ler üzerinde hızlıca dökümanlara ulaşabiliriz.
Örneğin, bilgisayarın kelimesi ile bir arama yaptığımızda hem birinci döküman hem de
ikinci döküman gelecektir. Eğer bir score mekanizmamız olsaydı birinci döküman daha önce gelecektir. Çünkü birinci dökümanda aynı terim 2 kez geçmektedir.
Bir diğer terim olan yazılım teriminde arama yapsaydık sadece 2. döküman gelecekti.
Belki aklınıza 1. döküman neden gelmedi sorusu gelebilir. Burada dikkat etmeniz gereken inverted index’e nasıl kaydedildiği olmalıdır. "yazılım" terimi ile yazılım terimi
aynı değildir. Bu yüzden biz yazılım diye arattığımızda "yazılım" terimi geçen
dökümanlar gelmeyecektir.